Source Qualifier is Active Transformation
Source Qualifier is connected transformation. It should be there in pipeline.
This is default transformation which comes along with source instance when you drag and drop into mapping area.But there is some exceptional case with XML and COBOL sources.
This is mandatory transformation to read data from sources and it converts the source data types to the informatica native data types. So, you should not alter the data types of the ports in the source qualifier transformation.
If we are not using Push Down Optimization, then every port of source qualifier should have link from source instance. Otherwise, workflow will fail.
If we are using Push Down Optimization, then at-least one port of source qualifier should have link from source instance. Otherwise, workflow will fail.
Source Qualifier Properties:
Below are the Source qualifier properties and there are enable when we are using tables as sources. In case of files as source, these will be disabled.

If we double click source qualifier transformation, we can see above properties window.
SQL Query:
We can pass the override query in this property. We can perform joins in the override query and we can filter out data by adding WHERE clause in override query.
If we are providing override query, we need to take care of order of columns. The order of columns in the override query should be same as the order of Ports in Port tab of source Qualifier.
If we open SQL Query property, it looks like below.

User Defined Join:
If we have two source instances and we are pulling fields from both the instances into one source qualifier, we need to provide join condition to get data. There are two ways to provide joins. One way is to use SQL Query property(explained above) and provide override query. Another way is to use "User Defined Join" property to pass join condition.
Lets assume there are two instances Employee and Department and we are joining based on employee number field. In this case, we need to pass below in this property field.
Employee.emp_num=Department.emp_num
We should not give ON keyword when we are passing user defined join.If we give ON keyword then workflow will fail.
Source Filter:
If we want to filter out records while reading from source, we can pass in this section. However, there is another way to filter out records in the override query. If we are not giving override query and if we want to filter records, we can use this property.
Lets assume we are using Employee table and if we want to filter records with employee number 100 then we need to give below.
Employee.emp_num=100
We should not give WHERE keyword when we are passing Source filter in this property. If we give WHERE then workflow will fail.
Select Distinct:
If we select this option then duplicate records will be eliminated, only distinct records will be populated.
Pre and Post SQL:
We can use these properties to execute any queries that needs t obe executed before and after execution of mapping. This is similar to session level PRE and POST SQL properties. Already a blog has been posted. We can get more details about these in the following link,
http://dwbuddy.blogspot.in/2014/01/pre-and-post-sqlsession-properties-at.html
Thank you and if you have any question, please do let us know.
Source Qualifier is connected transformation. It should be there in pipeline.
This is default transformation which comes along with source instance when you drag and drop into mapping area.But there is some exceptional case with XML and COBOL sources.
This is mandatory transformation to read data from sources and it converts the source data types to the informatica native data types. So, you should not alter the data types of the ports in the source qualifier transformation.
If we are not using Push Down Optimization, then every port of source qualifier should have link from source instance. Otherwise, workflow will fail.
If we are using Push Down Optimization, then at-least one port of source qualifier should have link from source instance. Otherwise, workflow will fail.
Source Qualifier Properties:
Below are the Source qualifier properties and there are enable when we are using tables as sources. In case of files as source, these will be disabled.

If we double click source qualifier transformation, we can see above properties window.
SQL Query:
We can pass the override query in this property. We can perform joins in the override query and we can filter out data by adding WHERE clause in override query.
If we are providing override query, we need to take care of order of columns. The order of columns in the override query should be same as the order of Ports in Port tab of source Qualifier.
If we open SQL Query property, it looks like below.
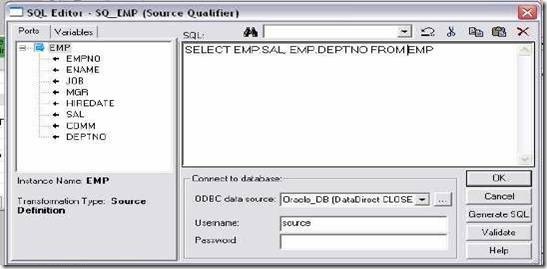
User Defined Join:
If we have two source instances and we are pulling fields from both the instances into one source qualifier, we need to provide join condition to get data. There are two ways to provide joins. One way is to use SQL Query property(explained above) and provide override query. Another way is to use "User Defined Join" property to pass join condition.
Lets assume there are two instances Employee and Department and we are joining based on employee number field. In this case, we need to pass below in this property field.
Employee.emp_num=Department.emp_num
We should not give ON keyword when we are passing user defined join.If we give ON keyword then workflow will fail.
Source Filter:
If we want to filter out records while reading from source, we can pass in this section. However, there is another way to filter out records in the override query. If we are not giving override query and if we want to filter records, we can use this property.
Lets assume we are using Employee table and if we want to filter records with employee number 100 then we need to give below.
Employee.emp_num=100
We should not give WHERE keyword when we are passing Source filter in this property. If we give WHERE then workflow will fail.
Select Distinct:
If we select this option then duplicate records will be eliminated, only distinct records will be populated.
Pre and Post SQL:
We can use these properties to execute any queries that needs t obe executed before and after execution of mapping. This is similar to session level PRE and POST SQL properties. Already a blog has been posted. We can get more details about these in the following link,
http://dwbuddy.blogspot.in/2014/01/pre-and-post-sqlsession-properties-at.html
Thank you and if you have any question, please do let us know.
Excellent article. Very interesting to read. I really love to read such a nice article. Thanks! keep rocking.Informatica Online Course Bangalore
ReplyDelete